General Matrix Multiply (GeMM)
In this section, you will learn about the following components in Spatial:
MemReduce and MemFold
Multi-dimensional Banking
Note that a large collection of Spatial applications can be found here.
Overview
General Matrix Multiply (GEMM) is a common algorithm in linear algebra, machine learning, statistics, and many other domains. It provides a more interesting trade-off space than the previous tutorial, as there are many ways to break up the computation. This includes using blocking, inner products, outer products, and systolic array techniques. In this tutorial, we will demonstrate how to build a blocked GEMM app that uses outer products, and leave it to the user to try and build a GEMM version that uses inner products. Later tutorials will show how to use shift registers and systolic arrays in other applications, but the same techniques can be retroactively applied to this tutorial on GEMM as well.
The animation to the right shows the basic way to compute C = A x B using outer products

Basic implementation
import spatial.dsl._ @spatial object MatMult_outer extends SpatialApp { type X = FixPt[TRUE,_16,_16] def main(args: Array[String]): Unit = { // Get sizes for matrices from command line val m = args(0).to[Int] val n = args(1).to[Int] val p = args(2).to[Int] // Generate data for input matrices A and B, and initialize C val a = (0::m, 0::p){(i,j) => ((i + j * p) % 8).to[X] } val b = (0::p, 0::n){(i,j) => ((i + j * n) % 8).to[X] } val c_init = (0::m, 0::n){(_,_) => 0.to[X] } // Communicate dimensions to FPGA with ArgIns val M = ArgIn[Int] val N = ArgIn[Int] val P = ArgIn[Int] setArg(M,m) setArg(N,n) setArg(P,p) // Create pointers to matrices val A = DRAM[X](M, P) val B = DRAM[X](P, N) val C = DRAM[X](M, N) // Set up parallelizations val op = 1 val mp = 1 val ip = 1 val bm = 16 val bn = 64 val bp = 64 setMem(A, a) setMem(B, b) setMem(C, c_init) Accel { // Tile by output regions in C Foreach(M by bm par op, N by bn par op) { (i,j) => val tileC = SRAM[X](bm, bn) // Prefetch C tile tileC load C(i::i+bm, j::j+bn par ip) // Accumulate on top of C tile over all tiles in P dimension MemFold(tileC)(P by bp) { k => val tileA = SRAM[X](bm, bp) val tileB = SRAM[X](bp, bn) val accum = SRAM[X](bm, bn) // Load A and B tiles Parallel { tileA load A(i::i+bm, k::k+bp) tileB load B(k::k+bp, j::j+bn) } // Perform matrix multiply on tile MemReduce(accum)(bp by 1 par mp){ kk => val tileC_partial = SRAM[X](bm,bn) Foreach(bm by 1, bn by 1 par ip){ (ii,jj) => tileC_partial(ii,jj) = tileA(ii,kk) * tileB(kk,jj) } tileC_partial }{_+_} }{_+_} // Store C tile to DRAM C(i::i+bm, j::j+bn par ip) store tileC } } // Fetch result on host val result = getMatrix(C) // Compute correct answer val gold = (0::m, 0::n){(i,j) => Array.tabulate(p){k => a(i,k) * b(k,j)}.reduce{_+_} } // Show results println(r"expected cksum: ${gold.map(a => a).reduce{_+_}}") println(r"result cksum: ${result.map(a => a).reduce{_+_}}") printMatrix(gold, "Gold: ") printMatrix(result, "Result: ") assert(gold == result) } }
The app on the left shows how to perform matrix multiplication using outer products and tiling. We will walk through the new constructs introduced in this code. The animation below shows the specific tiling scheme used in this example.

In order to generate a, b, and c_init host datastructures, we use the syntax that creates a Matrix. Specifically, this is (0::m, 0::p){(i,j) => … }. This works for datastructures up to 5 dimensions. To create c_init, we mark the iterators with underscores because they are not explicitly used in the function, which is normal for Scala.
For now, we set all of our parallelization factors to 1. In the next section, we will discuss these numbers further and explain the implications they have on the generated hardware.
In this version of matrix multiply, we choose to step across different tiles of C in the outermost loop, scanning the memory horizontally. There are other orderings of loops that will result in valid matrix multiply apps, but this is one of the variations that minimizes transactions with DRAM.
Because it is a general matrix multiply, there is no guarantee in the real world that matrix C is initialized to 0. Therefore, the correct thing to do is to accumulate on top of what is already in C. The outermost loop in this app is a three-stage coarse-grain pipeline. This prefetch line is the first stage.
We choose to use the MemFold controller here because we do not want the first iteration (k = 0) to overwrite what we just prefetched into tileC. We also create a local accum sram that will hold the partial result of multiplying two tiles together from A and B. This entire MemFold composes the second stage of the outermost pipeline.
Here we perform matrix multiply on the two tiles by using outer products. The outermost loop here is iterating across the inner, matching dimensions of partial matrices. In other words, kk is selecting a column from tileA and a row from tileB. The MemReduce and MemFold controllers must return an SRAM for their map function, so we create tileC_partial to serve that purpose.
The innermost loop of this algorithm is iterating over the rows of tileA and the columns of tileB. This is effectively performing an outer product (exhaustive pairwise multiplication) between every element in the two vectors selected by kk.
MemReduce returns the SRAM, so this particular MemReduce is the output of the map function for the outer MemFold. This is why there are two {_+_} lambdas that seem to be strangely redundant.
The final step, and the third stage of the outermost pipeline is the store that transfers tileC back to DRAM. The animation below demonstrates how to think of tileC as a triple-buffered memory.

We use the getMatrix and printMatrix functions here to fetch the data from DRAM and display the contents of these datastructures. Similarly, you can use getTensor3, getTensor4, and getTensor5, as well as their obvious counterparts for print for higher dimensional structures. Teh
multi-dimensional banking
import spatial.dsl._ @spatial object MatMult_outer extends SpatialApp { type X = FixPt[TRUE,_16,_16] def main(args: Array[String]): Unit = { val m = args(0).to[Int] val n = args(1).to[Int] val p = args(2).to[Int] val a = (0::m, 0::p){(i,j) => ((i + j * p) % 8).to[X] } val b = (0::p, 0::n){(i,j) => ((i + j * n) % 8).to[X] } val c_init = (0::m, 0::n){(_,_) => 0.to[X] } val M = ArgIn[Int] val N = ArgIn[Int] val P = ArgIn[Int] setArg(M,m) setArg(N,n) setArg(P,p) val A = DRAM[X](M, P) val B = DRAM[X](P, N) val C = DRAM[X](M, N) // *** Set mp and ip > 1 val op = 1 val mp = 2 val ip = 4 val bm = 16 val bn = 64 val bp = 64 setMem(A, a) setMem(B, b) setMem(C, c_init) Accel { Foreach(M by bm par op, N by bn par op) { (i,j) => val tileC = SRAM[X](bm, bn) tileC load C(i::i+bm, j::j+bn par ip) MemFold(tileC)(P by bp) { k => val tileA = SRAM[X](bm, bp) val tileB = SRAM[X](bp, bn) val accum = SRAM[X](bm, bn) Parallel { tileA load A(i::i+bm, k::k+bp) // *** Parallelize writer by 8 tileB load B(k::k+bp, j::j+bn par 8) } MemReduce(accum)(bp by 1 par mp){ kk => val tileC_partial = SRAM[X](bm,bn) Foreach(bm by 1, bn by 1 par ip){ (ii,jj) => tileC_partial(ii,jj) = tileA(ii,kk) * tileB(kk,jj) } tileC_partial }{_+_} }{_+_} C(i::i+bm, j::j+bn par ip) store tileC } } val result = getMatrix(C) val gold = (0::m, 0::n){(i,j) => Array.tabulate(p){k => a(i,k) * b(k,j)}.reduce{_+_} } println(r"expected cksum: ${gold.map(a => a).reduce{_+_}}") println(r"result cksum: ${result.map(a => a).reduce{_+_}}") printMatrix(gold, "Gold: ") printMatrix(result, "Result: ") assert(gold == result) } }
Here we demonstrate how banking works in Spatial, using tileB as our example memory. We base our banking calculation on “Theory and algorithm for generalized memory partitioning in high-level synthesis” (Wang et al), with minor modifications and improvements on search patterns.
Essentially, we attempt to bank a memory by looking at all of the accesses and finding a banking scheme that has no collisions. For more details, see Appendix A of the paper about Spatial. We attempt to bank an N dimensional memory in 1 dimensional space, and only if that fails or proves to be unnecessarily costly in resource utilization, we attempt to bank hierarchically.
Here we set mp = 2 and ip = 4. If you inspect the part of the app below where these parallelizations are used, you will see that mp parallelizes an outer pipe and ip parallelizes an inner pipe. The animation below shows one possible banking scheme for tileB under these parallelizations (considering only this read). Note that it is not the only valid scheme, and other hierarchical as well as other flat schemes exist.

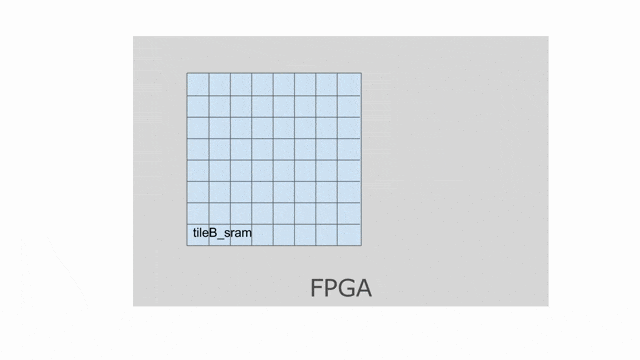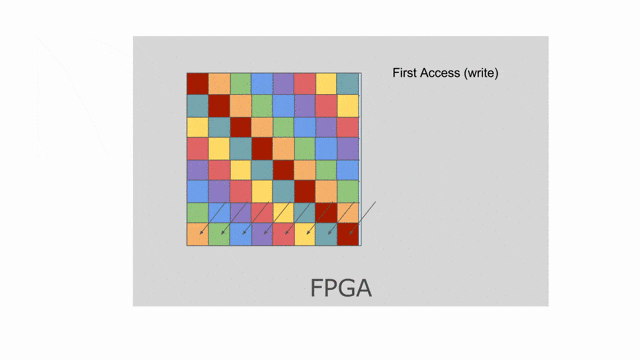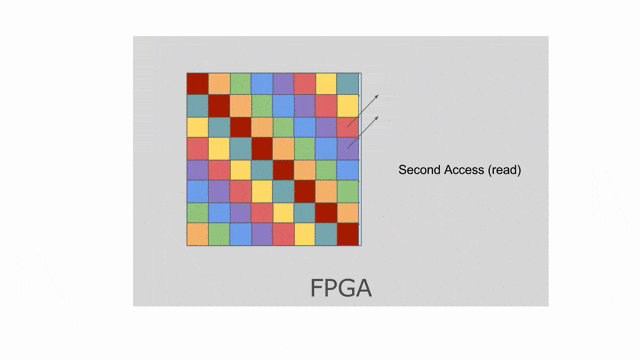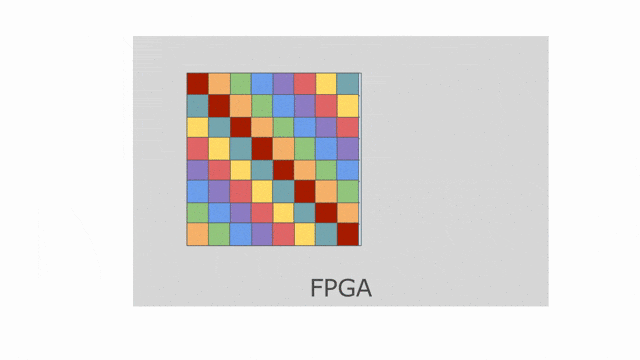
Here we choose to parallelize the writer to tileB by 8. This means the banking scheme above is no longer valid. We need to statically bank the SRAM and ensure that there are no bank collisions inside any of the accesses to the memory. In this kind of situation, the compiler will likely choose a flat banking scheme, as demonstrated by the animation below. Note that this animation only shows the reader with mp = 2 and ip = 1, but a motivated reader could experiment with these parameters in Spatial and see what happens to the memory.